The absolute best puzzle game for your phone
Sorry for the clickbaity title. I was slightly misleading.
Simon Tatham's Portable Puzzle Collection is not only the best puzzle game for your phone, it is actually a collection of the best puzzle games.
Wait! It is actually the best puzzle game collection for any device, since all games are playable via web (js and *cough* Java), and there are native binaries for Windows and UNIX.
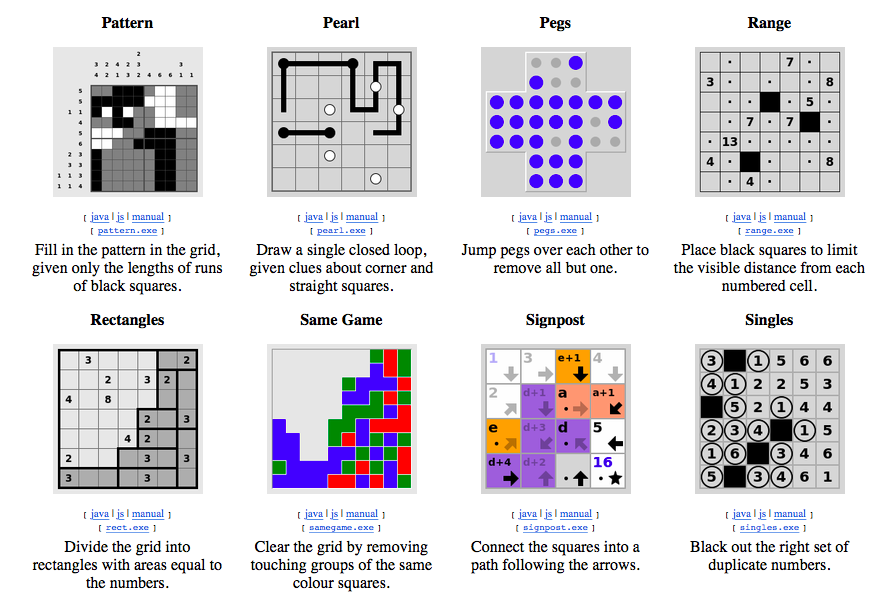
In Simon's own words:
[This is] a collection of small computer programs which implement one-player puzzle games. All of them run natively on Unix (GTK), on Windows, and on Mac OS X. They can also be played on the web, as Java or Javascript applets.
I wrote this collection because I thought there should be more small desktop toys available: little games you can pop up in a window and play for two or three minutes while you take a break from whatever else you were doing.
Simon's collection consists of very popular single player puzzle games, like Sudoku, Minesweeper, Same Game, Pegs, and Master Mind, and some lesser known, at least for me, but extremely fun to play: Pattern, Signpost, Tents, Unequal.
All games are extremely configurable and can usually be learned by reading the instructions and trying to play on a small board where the solution is usually trivial. Then, when you are ready, start expanding the board size and enabling some of the higher difficulty board generators!
Greg Hegwill ported the games to iOS and Chris Boyle ported them to Android. Other people have ported it to more platforms, like the Palm, Symbian or Windows phone

The games can of course run in old devices, are 3x free (money free, free software, and free of ads) and, as context,
each game takes around 300kb of space (yes, kb). The full collection weighs 3.5Mb on iOS.
For reference, Simon's mines.exe is 295kb, where Windows 3.1's winmine.exe was 28kb.
Simon's last commit is from April 2019 and he is still adding improvements to make the games more fun.
I don't really know how this could not be the Best Puzzle Game Ever. Download it right now on your phone (iOS, Android) and you'll thank me later.
Sourcehut, the free software development cloud
I've been following sourcehut for some time and realized that I hadn't talked about it yet.
Sourcehut, at a first glance, is a service that provides git repos and code/project management tools, but it's much more.
It runs CI through virtualised builds on various Linuxes and BSD, provides code review tools, tasks and third party integrations, and of course, mailing lists and wikis.
I think the landing page does a good job of explaining how it is different from other code hosting services. Especially:
- Composable Unix-style mini-services
- Powerful APIs and webhooks
- Secure, reliable, and safe
- Absolutely no tracking or advertising
- All features work without JavaScript
- 100% free and open source software
These bullet points are quite important: sourcehut is the web equivalent of piping UNIX commands for development and is built entirely on free software. The fact that it works without js is just a great bonus.
Sourcehut is the project of a single developer, Drew DeVault, better known as sir_cmpwn on the internet, and he's quite active on Mastodon in case you want to follow him. Amazing work!
La predicción del tiempo en tu calendario
(Even though I write my blog in English, this post is in Spanish for obvious reasons. Click here to translate it with Google)
Si te pasas el día mirando el calendario, agendando reuniones y eventos, y echas en falta tener a mano el tiempo que va a hacer, he creado una utilidad que te puere resultar muy interesante.
Se trata de mostrarte la predicción del tiempo en tu municipio en el mismo calendario
Es muy sencillo: escribe el nombre de tu municipio y pulsa el botón. No hay que registrarse, ni dar tus datos, ni pagar nada. Es una herramienta simple y anónima.
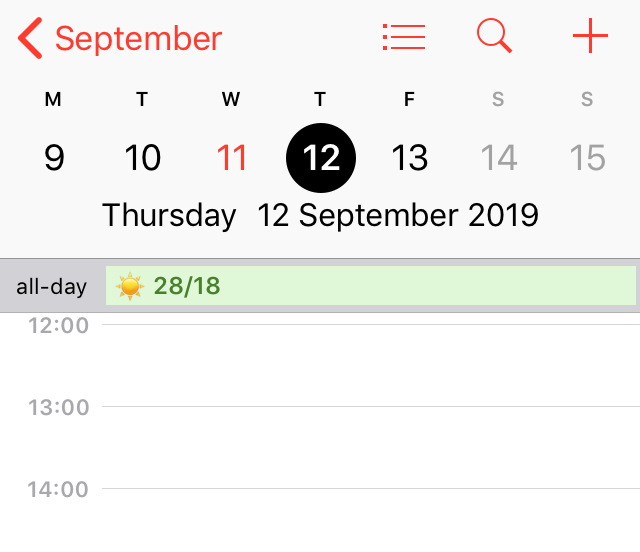
Es compatible con todos los teléfonos y ordenadores ya que usa tecnologías estándar. Tu dispositivo se encargará de ir actualizando las predicciones de manera regular.
Creé esta utilidad para mi uso personal al descubrir que no existía nada similar, y tras usarla unas semanas pensé que podía ser útil dar acceso a los demás.
Los datos están sacados de AEMET por lo que sólo funciona en el territorio español.
Tienes el enlace aquí: el tiempo en tu calendario
Tags: software, projects, spanish
mosh, the disconnection-resistant ssh
The second post on this blog was devoted
to screen and how to use it to make persistent SSH sessions.
Recently I've started using mosh, the mobile shell. It's targeted to mobile users, for example laptop users who might get short disconnections while working on a train, and it also provides a small keystroke buffer to get rid of network lag.
It really has little drawbacks and if you ever ssh to remote hosts and get annoyed because your
vim sessions or tail -F windows get disconnected, give mosh a try. I strongly recommend it.
A simple script to postpone your own email
I somewhat use email as a task manager. Honestly, I believe we all do. We process emails in the inbox, then archive or delete them when we are done with them.
However, keeping track of emails that need a follow-up on a specific date can be difficult.
Around 2011 I wrote a script to perform that task. It is a very simple IMAP parser that searches for a folder with today's date and moves all its contents to a special folder named "Today".
Let me tell you my email workflow. I understand that not everybody works in the same way, but maybe you can get some ideas to improve your email handling.
My email folder structure looks like this. The interesting part is in bold.
Inbox
\_ Mailing lists
\_ Project folders
\_ ...
\_ Deadlines
\_ Today
\_ Tomorrow
\_ 2016-01-19
\_ 2016-02-02
...
\_ 2017-08-01
I follow the GTD methodology, which essentially states that tasks should either be done on the spot, delegated, or deferred. Thus, my inbox is exclusively for new tasks. A couple of times a day I process incoming email and, like most of us, either delete it, reply to it, forward it or —this is the interesting part— move it to one of the "Deadlines" folders.
Instead of using the inbox as the "email task manager", I use a folder named "Today". I've tried both alternatives, and I find that it works best for me. Since it separates new tasks from tasks I've already processed, I can work my entire day on "Today" and totally forget about the Inbox, even if new email is arriving.
The "Tomorrow" folder is just a shortcut so that I don't need to create a new folder with tomorrow's date every day.
As you may have guessed, the script runs once a day in a crontab, at 6 AM, and moves all mail from "Tomorrow" and the folder with tomorrow's date to "Today". That's it. And that "simple trick", as fishy marketers like to say, saves me a lot of time and headaches every day.
There is currently a commercial alternative, Boomerang, which you may find interesting if you aren't comfortable with programming. I haven't used it, so I can't comment on that. In any case, I usually prefer writing a small script rather than using a third-party service.
Update: this script by Alex Kapravelos does something very similar, and it integrates with Google Apps Scripts.
Here it is, as a Gist. The code is definitely not the best in the world, but it works. Feel free to use it, modify it (BSD license), give feedback and leave comments.
I hope that you can introduce some ideas from this methodology to your daily workflow. it can be as useful as it's been for me.
Tags: software, tricks, productivity
Puput, mail without internet
Here's my new project: Puput, a service which lets you listen to your email when you have no internet.
I honestly think it's pretty cool, the project has a strong R+D component for which we filed a patent, and it has lots of potential to integrate into IMs like Slack and close the communication gap for people who are offline.
It's free, so please be my guest and give it a try! It's surprisingly awesome to be able to listen to your email when you're abroad without an internet connection.
Even though we have been absorbing a lot of startups-related material these last months, nothing will prepare you for a real product launch. Everybody says it, and I agree:
- The last 20% of the work consumes us 80% of the time. That is, UI, UX, the website, and the marketing strategy
- Selling is hard.
- Selling is even harder when you first invent a new technology and then try to find use cases for it. Yes, the lean startup recommends doing the opposite, it is a common first timer mistake :(
- I'll say it again, do product/market fit first, then start coding.
- Raising money is nearly impossible in the Spanish startup scene. Obviously we're nobodies, but I've also talked to many other founders, with great products, thousands of clients and two-digit monthly growth, who find it incredibly frustrating to raise even 200k€
- Launch day is scary so you find excuses not to launch. Adding more features is one of them. Establish hard deadlines and try to respect them as much as possible.
- It turns out it isn't that scary anyways, in fact, getting users and attention is difficult at first. Dying from success is unrealistically represented in sites like HN, it doesn't apply to 99% of the startups.
Anyway, launching a product is hard, teaches you many things about the world, and makes you respect people who have done it successfully.
Cheers to all first time founders.
Tags: internet, software, startups, projects
OpenBSD from a veteran Linux user perspective
For the first time I installed a BSD box on a machine I control. The experience has been eye-opening, especially since I consider myself an "old-school" Linux admin, and I've felt out of place with the latest changes on the system administration.
Linux is now easier to use than ever, but administration has become more difficult. There are many components, most of which are interconnected in modern ways. I'm not against progress, but I needed a bit of recycling. So instead of adapting myself to the new tools, I thought, why not look for modern tools which behave like old ones?
This article discusses some of the main differences between OpenBSD and Linux, from a Linux admin perspective.
There are some texts on the net discussing the philosophical differences between BSDs and Linux, but not many of them are really hands-on. This one is the best, and I recommend you to read it along with this one.
Since I am new to OpenBSD, I may get some things wrong. Please email me any corrections. However, my goal is to point out my first impressions, so if there are any Linux users reading and thinking about making the jump, they can know what to expect.
Final update: I've received a huge amount of feedback from this article, overwhelmingly positive, and very welcoming from the OpenBSD community.
This text's goal is to discuss an OpenBSD newbie's first impressions and, as such, I'm realizing that some parts aren't totally accurate. However, I want to keep that perspective, so in the future I'll prepare a more technical guide on how to migrate to OpenBSD for Linux users. Thanks everyone!
The "RAMDAC" running joke
First, some background about my Linux experience.
My first computer was a 386 with DOS and Windows 3.1. I had played with Spectrums, Commodores, and IBM PCs (8086). I followed the traditional Windows path: 3.1 -> 95 -> 98 -> ME -> 98 -> 2000. But I always liked computers, and the most visible part of them, besides the hardware, is the OS.
I tried to install my first Linux distro on 1999. It was a Red Hat Linux 5.2, if I remember correctly, and I got the CD from a magazine because I was still running a dial-up. I was 15 and I thought I knew computers, after all, I had assembled my own, an AMD K6-2 box, from parts.
Red Hat proved me wrong.
- Which is your chipset?
- Man, I don't know
- Which is the model of your RAMDAC?
- What is a RAMDAC?
- I need your monitor modelines. Don't get them wrong or you will physically damage your CRT
- Dude, I'm 15, I can't afford to break anything!
{kind=link}
In the end I didn't break my monitor, but
got a black screen which said login:, and didn't know what to do, so I booted back
into Windows and played a bit of Warcraft 2.
In that age we only had one computer, so if you were installing something and needed help, you had to stop, reboot into Windows, dial up the modem, search the Usenet or forums, write down the solution on a piece of paper—no ubiquitous printers—, hope you got the commands right, reboot, start the installation over, reach the point where you previously were, and apply that solution. Not practical at all.
The best help we had were books, and those were expensive and difficult to find on a small town bookstore. For those of us not fortunate enough to buy/find books, we had hobbyist magazines. In Spain there were a few imported and poorly translated magazines which were expensive, but carried some CDs, the only practical way to get distros.
The first Linux I really was able to use was Mandrake 6.0. It had a graphical installer—not that having graphics
made any real difference on the final result— but it auto detected my hardware correctly and booted into X. Yeah!
Old Linux software!
A game called Nethack which had nothing to do with hacking! sysconfig!
{kind=link}
Unfortunately, I couldn't connect to the internet because of my Winmodem, so after a few days of tinkering, Mandrake was wiped too.
Months later, I got myself a BeOS CD. It was like Linux, which for me, then, meant it was not Windows. The setup ran totally effortless and it even detected my Winmodem. The internet ran faster than on Windows. It had a great internet browser, mail and newsgroups clients. Oh, boy! I used BeOS for a long time almost exclusively and only booted Windows to play some games.
A couple years later I started Computer Engineering on college, so I wiped out everything and installed Linux. I got a new machine and a real network connection.
I've run lots of Debians, Red Hats, Mandrakes, Gentoos and Slackwares. We used Solaris and even some VAXes. I ran some servers for student organizations, and finally settled on Debian as "the best" distro: stable, easy to use, no need to compile on our 486, nice hardware detection and with a big community.
Finally, I moved to Ubuntu if only because its LTS releases. Around 2006 I got into Macs, which at first seemed like a nicer Linux, and now I appreciate the hardware+software combo for which I know I won't have to fight with its drivers.
In summary, I've seen a lot of UNIX, even more Linux, and administered a good chunk of them. My servers have always run some sort of Debian.
You could say that as I grew older I also grew tired of fighting with RAMDACs, modelines and Winmodems. Each age brought new "RAMDACs": CD recording, wireless card support, laptop hibernation, webcams, divx playing, DVD playing, NTFS support...
Linux always worked in the server but had some quirks in the desktop which made it somewhat unattractive for daily use, even when I run it exclusively on my laptop.
Nowadays, Macs offer a UNIX with some peace of mind, and the current status of Linux is good enough. Some of the friends I evangelized long ago—I quit doing that—still use Ubuntu and are happy with it. Linux may never triumph on the desktop (or laptop), but it's good enough for most.
Upgrading a G4 Mac Mini
Now jump to 2015. My home server, a G4 Mac Mini, was already two Debians behind. Some packages weren't ported to powerpc. I needed to perform a clean install and upgrade the whole system either way. But this time I didn't want to use a Linux installation which wants me to reboot every 5 days because of some critical patch. I'm looking at you, Ubuntu.
As you can imagine my operating system fascination didn't fade out, only my time. I had been closely following the BSDs and using a NetBSD shell account, installed Plan 9 on a virtual machine, and even wrote a toy OS project.
I'm not afraid of compiling stuff—I do it for a living— and may even be open to modifying some code if needed. Why not try something new?
Since I had the weird powerpc requirement, I ruled out most operating systems. Finally I decided to play relatively
safe and go for a BSD. FreeBSD is the most popular, has
more online HOWTOs, and probably more features (ZFS, Jails), though I probably would not be using them. OpenBSD
is more hackable, seems to have better documentation, and some cool people I know use it. I didn't want to quit using a pot
to start using a kettle, so I downloaded OpenBSD's install57.iso
It was impossible to boot the Mini with a USB stick; I'm unsure if it's the firmware's fault
or the fact that I was dd'ing the .iso file into the USB instead of the .fs one which doesn't seem to be available
for macppc.
I found some blank DVDs on a closet, borrowed a computer with a DVD drive—another medium I hadn't touched in years—, and burned the ISO image. The fact that I recorded the first disk with the ISO file on the root folder instead of properly burning the contents into the DVD warned me that this was going to be hard, but fun...
Surprisingly, the installation was straightforward, it detected the 10-yr-old hardware, and by following the instructions I managed to partition the disks and install the boot loader. The box was up and running.
Well, that wasn't so hard, was it? Now, to restore my old installation.
Hm, first of all,
bash needs to be installed from packages and goes into /usr/local/bin, so I had to
modify a lot of scripts which pointed to #!/usr/bin/env bash. The ps and tar commands have slightly different
switches which broke other scripts.
The base services are different; OpenBSD includes its own HTTP, SMTP and NTP servers. Configuration files
are in different places. Here goes my week...
GNU is really not UNIX
A quick note on the GNU/Linux naming discussion, since GNU is entering the equation now. I use the term "Linux" for simplicity. I know that's the kernel name. It also happens to be the popular name, even if not totally correct—according to some.
Here is some food for thought; why does the FSF deserve more credit on the name than, say, the Apache Foundation, or the FreeDesktop project, or BSD, for that matter? Why don't we include every key component on the name and call it GNU/FreeDesktop/Apache/OSI/BSD/.../Linux? Including only GNU would be unfair to other big contributors, wouldn't it? So let's please stop this fight.
That being said, the GNU tools and design philosophy make a noticeable difference in administration and userspace, and one can only appreciate it when switching to a different environment.
I don't want to overstate it, though. Thanks to POSIX, a Linux admin can run BSD with little extra effort, since most of the things are similar. There are, in fact, more similarities than differences. If FreeBSD and OpenBSD are brothers, then Linux is a close cousin.
ls is always ls. mkdir is mkdir.
But when you're being used to /dev/hda, free -m and cat /proc/cpuinfo you realize that having a different
kernel is naturally going to change some of the administration tools.
Some say that the GNU tools are bloated and that the BSD toolchain is more "pure UNIX". The reality is that it depends on the specific GNU tool, I've personally found that GNU tools are more complex because they're more powerful, though they are less UNIX-like (do one thing only and do it well) and more like complete solutions. That's fine; different, but fine. After all, GNU is not Unix!
In recent years, the Linux environment has grown in the GNU toolchain fashion, not the UNIX fashion. One may even say it has grown in the Windows fashion: be practical, be accommodating to all, be fast, be modern.
There have always been debates about "bloated and complex code". More recently, systemd. Previously, Apache, sysconfig, iptables/iptools.... The list goes on and on. Wheel out comp.os.linux and look at the flame wars.
No software fits all nor should be shamed for its design decisions. In the end, with a few critical exceptions like OpenSSL and the Heartbleed bug, it is just a matter of taste: does the admin prefer simple, pluggable services, or bit monolithic suites? Compatibility or modernness? Familiarity or shiny new things? Standards or NIH?
I had been riding the Linux wave for years, until I recently realized that my admin skills needed a total
recycling. In a few years we've gone from /etc/init.d/sshd restart to service sshd restart to systemctl start sshd.
That's a bit fast in my opinion, but I understand it's the price of progress, aimed to make computers boot
faster and theoretically easier to administer for newcomers. Old admins, on the other hand, have a harder time adapting.
Having to choose between recycling into an always changing Linux or a more stable UNIX environment, I chose OpenBSD. Given my history of trying all possible OSs, Let me state again that I'm not against the recent Linux direction. I just wanted to go out and see if there is a different way to do things.
Differences between OpenBSD and Linux
Maybe you're reading this article for its practical value and not for my ramblings, sorry. I thought I had to provide some context. I'm used to googling, I'm used to RTFMing, I'm used to reading source code to learn what software does. This context is important to judge if you would notice the same differences as I did.
Here's a list of things that surprised me the most after completing an OpenBSD install, adapting my old setup to the new environment and running it for a few days.
Simplicity
First of all, everything is much simpler, like the Linux old days. Not necessarily easier, but simpler. More minimalistic. I found this plays well with my mind. OpenBSD follows the UNIX philosophy more closely: lots of small components that do one thing and talk between them by passing text.
Because of that, some base components are not as feature-rich, on purpose. Since 99% of the servers don't need the flexibility of Apache, OpenBSD's httpd will work fine, be more secure, and probably faster. For those who need the big boys, just install Apache from the packages.
Having a developer-chosen default option for many servers is a time saver. The admin knows it will be well supported and documented, and tightly integrated with other components. The alternative, the Linux way, is to just use what everybody else uses (Apache), or choose one of the multiple options, always wondering if it's the right one—nginx? lighttpd? thttpd? You know what... nobody got ever fired for choosing Apache
Design decisions
Picking up on that thought, the system is very opinionated. When the community decides that some module sucks, they develop a new one from scratch. OpenBSD has its own NTPd, SMTPd and, more recently, HTTPd. They work great.
Likewise, the standard shell is pdksh. The OpenBSD FAQ states that
"Users familiar with bash are encouraged to try ksh(1) before loading bash on their system -- it does what most people desire of bash.",
which is a bit too bold. ksh does not support history substitution (sudo !!:1) which I use a lot, though I agree
that for many users it will be enough. Many people hate bash for a reason, I am not one of them.
Having a super powerful shell has saved me from writing perl scripts for system administration.
Bash can always be installed from packages, anyway.
This is a big difference from Linux, which is more like a "consensus" operating system. Developers have to keep compatibility and whenever there is a controversial design decision like systemd, dozens of projects decide to fork. Not good.
Strong opinions, on the other hand also lead to less support for some, like ext4, ZFS or Linux binary compatibility. For example, ext4 is officially supported read-only but in my case it didn't read some folders properly. FreeBSD plays better on that regard, though they also have more developer manpower. This leads to some use cases, like an OpenBSD desktop, being possible but not the best choice for this OS.
Finally, other decisions make little sense. According to disklabel(8), the /usr partition takes about 2G of disk space, not including /usr/src or /usr/obj. This means that there is little space to hold what is essentially the whole system plus ports. I had trouble compiling large ports since /usr ran out of disk space. If a large number of users will be compiling some ports, why not set a larger /usr by default?
Documentation
The man pages are excellent, a delight. Unlike Linux, they are not just a list of switches for the software, but a comprehensive guide to the tool, with lots of examples. They are much, much better—thankfully, because unlike Linux, again, there are not tons of help on public forums.
OpenBSD's man pages are so nice that RTFMing somebody on the internet is not condescending but selfless.
Granted, I wouldn't make a UNIX novice run OpenBSD from man pages, but for an experienced admin, they contain exactly the information they need.
Small differences in common tools
Using the BSD toolchain instead the GNU one means there are small differences between tools.
For example, some ps switches are missing, like the useful -f. The tar options for reading from stdin
are also slightly different. When ls is run by root, it automatically appends all hidden files.
df has -h (human) and -k (kilobytes), but no -m for megabytes.
If you've used MacOS you probably know a few of these.
Packages
OpenBSD has packages, like Linux. Unlike it, packages are only available for 3rd party software, not the base system.
OpenBSD's base system is more or less what gets installed from the CDs: kernel, shell, coreutils, a small part of X and essential servers (http, ntp, smtp, etc.) Everything else must be installed from packages.
The documentation recommends using packages, since it is not worth it to compile from ports—the package sources. However, packages don't get security updates. The only way to patch bugs is to compile the ports.
Fortunately, there is a simple way to use the best of both worlds: add FETCH_PACKAGES=yes to /etc/mk.conf
and install software from ports. The system will automatically fetch the package and save the compilation
time if there is a current binary available.
Another interesting tool is /usr/ports/infrastructure/bin/out-of-date, which checks which ports need
an update, so you can go to /usr/ports/<portname> and make update. This command plays well with previously
installed packages, so you don't have to worry deleting them first.
In summary, after you install the release, if you're interested in getting security updates until next
release, the officially recommended path is to follow -stable, use FETCH_PACKAGES and work from ports.
This is not very clear in the documentation but the folks at #openbsd
helped me figure it out.
As a colophon, if you're using x86 or amd64, m:tier provides binary updates for the base system and packages, much like Linux does. Otherwise, if there is any bug in the base system you'll need to recompile that part yourself. The amount of compiling needed will be determined by the patched component and any related software, so just read the instructions on the patch.
Configuration files
The base system config files are properly centralized in /etc, but
not the ports. The porting quality is excellent, better than any Linux distro. Every port is adapted
to the OpenBSD system and made sure it behaves correctly. However, some maintainers decide that all
the port files need to be contained in some folder, like transmission-daemon, which stores its
config into /var/transmission/.config/transmission-daemon/settings.json. It's a bit crazy to store
a system-wide daemon config file into /var which, according to man hier, contains
Multi-purpose log, temporary, transient, and spool files.
Apparently some daemons are chrooted by default, and there is a global "catch-all" README folder
on /usr/local/share/doc/pkg-readmes which contains specific info about packages. transmission-daemon
had no related info, so maybe I'll contact the maintainer.
Chroot
Speaking of roots, nearly all daemons in the base system are chrooted and privstep by default. The base system has a lot of hardening by default, which is one of the main reasons why OpenBSD has almost no remote holes on the default installation.
Since chrooting software in Linux can be cumbersome, it's very convenient to get it done for you, so thanks!
Experienced community
I feel like the learning curve is a feature, not a bug, intended to keep newcomers away. OpenBSD is unapologetically elitist. Honestly, I don't mind that. I've been administering systems for more than a decade and not all environments are for everybody.
OpenBSD can afford to be elitist because it is a small system, with a clear direction, the documentation is crystal clear, and it doesn't make vague promises.
make build
As you can see there is a big con to using OpenBSD coming from a Linux world, the process for patching security issues. On Linux I was used to run a single command and let any part of the system (base or 3rd party) update itself. With OpenBSD, it takes a lot more effort and time, especially in my old machine.
This process leaves the admin only one realistic option: follow the -stable branch, which is basically the same code as the CD release with small patches, and recompile stuff regularly. Otherwise, the installed system will be exposed to potential security holes until the next release.
I feel that this needs to be more prominent in the OpenBSD docs, especially on the Migrating to OpenBSD
section: if you want an updated and stable
system you'll need to recompile stuff constantly, there is no equivalent to apt-get upgrade.
To get a secure production system with OpenBSD, the officially recommended path is to:
- Install the CD release
- Download the source code
- Recompile the kernel (recommended by "following -stable")
- Recompile userland
- Download ports tree
- Add
FETCH_PACKAGES=yesto/etc/mk.confto let ports fetch packages, if available, and install software using the ports syntax. - Recompile when there is a security issue which affects your setup, though you may skip some compiling if using m:tier.
Of course, this is a feature, not a bug, but it's the biggest admin change from old Linux users.
That's a lot of effort compared to apt-get update && apt-get upgrade. Honestly, had I known it,
I would've more strongly considered keeping my Debian installation. I read all the online documentation before
installing OpenBSD, and I felt like this point wasn't really clear.
Since you can safely use -stable ports/packages with a -release base system, steps 3-4 can be avoided or shortened if you don't want to update your base to -stable. That's what I would recommend to former Linux users, but take this newbie's advice with a grain of salt.
In any case, for low-performing machines like mine, maybe the "recommended" path to follow -stable and rebuild the source for every errata is not the best one. For small fixes it may be better to just apply the patch and follow its instructions. Apparently in faster machines it's just more convenient to recompile the base system since it takes just a few minutes. Had I been using x86 or amd64, I'd have totally gone for m:tier, so you can dismiss this section if that's your case.
To be totally fair, it's rare for OpenBSD to have remote holes on the CD release, so one could be relatively safe by only upgrading from release to release. But the truth is that there is no simple way to binary patch for critical updates unless using the third-party m:tier on one of the supported architectures.
With that it mind, to summarize, there are the following options:
- Use a -release base and -stable ports (with
FETCH_PACKAGES=YES), cherry-picking patches from base and updating ports bymake update. This may be the recommended path for low-performing machines - Use a -stable base, too. You can then update the whole system with a handful of commands and won't need to follow patch instructions
- Use -release and update from m:tier
- Keep using -release until a next -release comes, unless there is an unlikely remote hole that forces you to recompile the base. This may be the best option for newbies if the only person using the box is the admin, so there is no way to suffer local attacks.
Update: OpenBSD now supports binary updates for security, like apt-get upgrade.
Check out the announcement
and the official documentation
which has been updated to reflect this much easier process: just run pkg_add -u
Conclusion
From a user perspective all of this is transparent; OpenBSD has a UNIX terminal or Xwindows session and everything works as expected. But a Linux admin will need to adapt to these new tools and allocate some more time for administration.
OpenBSD has pros and cons. Personally, my main pros are the excellent documentation, its minimalism and the choice of default daemons. The only con is the need to recompile to patch errata. If I had just one wish for OpenBSD, it would be a more straightforward updating system for security errata.
Now, the dreaded question. Is it worth it?
Honestly, I wasted too much time. Some of it was to be expected, since I needed to learn a different environment. Had I been 10 years younger, this wouldn't have been a problem, but my time is more limited now. The fact that I needed to compile things on an old machine probably didn't help. Keep that in mind when considering a BSD for an old, weird architecture.
After the initial investment, I want to see if maintenance is easier and release upgrades are smoother than with Debian. Manually upgrading things is a pain in the neck, but all other factors lead me to think that OpenBSD is a great server OS.
Maybe I was expecting something else from the docs I read? It is probably my fault, though. Anyway, I want to contribute to the available documentation by writing this document so that other Linux admins can make a more informed decision.
On the other hand, my geeky side is content. OpenBSD rocks. It is a different—a real—UNIX and I've really come to appreciate simple code and software. As an admin, having minimalistic, default servers is a blessing.
Again, should you try OpenBSD? The answer is yes, though be careful if you're either in a rush or have specific software requirements. The first days are a bit hard, and recompiling on a slow machine takes time.
If you like UNIX, it will open your eyes to the fact that there is more than one way to do things, and that system administration can still be simple while modern.
Revised with contributions from TJ and Mike. Thanks!
Filter tweets in Safari
I've been looking for a Safari extension which filters tweets by keywords for some time. Most were abandoned and none of whem worked with the current Twitter layout, so I decided to learn how to code Safari extensions and see if I could code one.
Writing a Safari extension is simple since Apple provides an Extension Builder within Safari and there is a nice tutorial on Macworld which helped me quite a bit. Apple's documentation is good too.
I had to spend about 90% of the time wondering how to retrieve the settings from the extension, which requires a convoluted process involving message passing between two Javascript classes, but in the end it seems to work.
It is election time in Spain, so get the extension from Github and get rid of those pesky political tweets without needing to unfollow anyone!
Tags: software
Creating an OS from scratch
I am a Computer Engineer major, so I took some classes in college on how to build operating systems. For many reasons, I don't remember most of it, but it is a world which has always excited me.
There has been a recent post on HN which points to a very simple and detailed tutorial on how to write an OS from scratch and it has really inspired me, so I decided to create a Github repo to publish the code at the same pace that I learn to write it.
It is not for everyone; rather, for CS/CE majors who were overwhelmed by college but always were curious about what happens from the moment you turn on your machine up until when an application loads.
I split each "lesson" into one-concept increments, so it can be easy to follow for people like me who don't have a lot of time and brain power to learn at a University pace. This is a work in progress, again, I publish code while I learn and extract it from the original document and other internet resources, so expect it to be updated regularly!
Spotify, we need to talk
Spotify, I pay you 10 euros every month just for one reason: so that I can listen to my music when I'm in the car.
I'm so glad you exist, you give me a reason not to pirate music. I had expected a service like you for a long time. I used to tell my friends that "I'll stop pirating when paying gives me a better experience than torrenting". And you did that. I was so happy to pay you every month. I have convinced at least three people to subscribe to your service, under the premise that they will be able to listen any track, anytime.
Last week, your app was updated again, but since iOS 7, this was done silently. And alas, I jumped into my car to start a road trip, connected to the bluetooth system, and voila! None of my music was there.
Well, it was there, but it didn't play. Of course offline playlists didn't play. But not even my own local files did play. Ironically, the only music I could play was the one I hadn't download, thus accessing it via 3G streaming.
This needs to get fixed, right now. In the next release. I mean, not even my local files?! What did you do with them? They are plain mp3 files!
Furthermore, with every release it gets worse. Your engineers spend time making the app "cooler" and enhancing the design, but it works way worse today on my new phone than two years ago on my old iPhone 3GS. How is that acceptable? Who checks your QA?
If I jump again into my car and you have deleted all my music, I'm back to downloading mp3s and advocating torrenting. Get your stuff together, Spotify.
Tags: software
Use whatsapp from the command line
Update Oct 2014: Whatsapp changed their protocol and third party clients like yoswup may not work anymore.
In this post I'm going to show you how to run a commandline Whatsapp client. It can be very useful to connect it to a unix pipe and automatically get messages from your server, via Whatsapp. Also, it's cool B-)
Disclaimer: Whatsapp is sending DMCAs to take down Yowsup's Github repos, so either the software or the process may break with any update of their protocol. However, to date, I've been using it for a couple of months with no hassle.
- Download Yoswup from Gitorious and extract it somewhere
- Edit the config file and input your cc, phone and id. Leave the password blank
- We are going to force a re-auth on your phone's whatsapp in order to cache the password.
Authenticate with yowsup:
./yowsup-cli -c config -r smsand wait for the SMS - Second step of the authentication:
./yowsup-cli -c config -R [6-digit sms code] - Now your phone's Whatsapp is disabled. Open the app and re-auth with either a SMS or a phone call, whatever is available first. You may have to wait some minutes.
- Download iFunBox
- Connect your phone, open the iFunBox app in your computer, and navigate to
whatsapp/Library/Caches/net.whatsapp.WhatsApp - Copy all files named Cache.db* to some place
- Download SQLiteStudio
- Open SQLiteStudio, and open the database on Cache.db. Navigate to the table
cfurl_cache_receiver_dataand scroll to the end. You will see a large json string. This is your current authentication data. - Look on the json string for
pw:XXXXXXX. That's your password. Copy it to yowsup's config file - We are ready!
./yowsup-cli -c config -s [cc][phonenumber] "I'm texting you from a terminal"
Enjoy! Yowsup can also be used for full conversations, send messages to yourself which you'll receive on your phone or, as mentioned in the beginning of this post, pipe some other command to your phone.
SQLite: a standalone database for your application
Us researchers are used to store data in plain text formats, because it's very easy to parse and work with. While this is appropriate for some data types—and, I'd add, very useful to send later to R—, in some cases disk access is slow or just inefficient.
This topic is actually very important for some projects, as storing records into a plain text file is very slow to query afterwards. And this is the key question to ask ourselves before considering to use a database. Databases are great for complex, unordered queries, but not so great for sequential access of raw data. Let's see an example.
There is a data file which stores atom coordinates, for example, from a Molecular Dynamics simulation. This data is very likely to be read once, sequentially, then processed in memory. The information represents a matrix which will be processed by mathematic functions. This is the classic example where data files (either binary of plain text) are used correctly.
But now let's think of a list of proteins and some properties, for example, molecular weight and number of available 3D structures. All these objects are independent, they have their own entity. While you can store a text file with one line per <protein, weight, structures>, it makes more sense to store it on a database.
Databases allow complex queries to be resolved very quickly. For example, give me all proteins with molecular weight > 50,000 , list all proteins which have no crystal structures, or print all the proteins which have duplicate structures. Were we working with a text file, we would need to process it completely every time we perform a query. That's very, very slow. Databases internally store the information in such a way that queries don't need to go through all elements to get the answer. Namely, they store data on trees by indices.
How do indices work? It's a complex issue but let's think of a very basic example. Let's say you have three protein structures (1BCD, 2KI5, 1AGI) which you want to index by name and molecular weight. The system will then automatically build a protein binary tree where 1BCD is the parent, the left child is 1AGI and 2KI5 is the right child. Then, it will create another tree where the left child is the lightest protein, the parent is the middle one, and the right child is the heaviest one.
If the index tree is always sorted where the left child is alphabetically inferior than the parent, and the right child is always superior to the parent, then we can access any element or group of elements not only without checking every item but also in logarithmic time. Databases do this once for every index you configure, so complex queries can be solved super fast because for each of them the system only needs to process a few items of the many millions you might have stored in the DB. That's because every time you jump to a child element, the system is avoiding to process half of the database, then a half of this half (1/4), then 1/8, etc.
To summarize, if you have some data where each record has its own entity (i.e. can be thought of as an "object") and you think you'll make queries which retrieve an arbitrary number of the elements, then you need to use a database. Databases have even more advantages, like relationships between objects (e.g. each crystal structure has its own entity, and can be related to a protein), but database design is a complex topic and this article will cover only the basic data storage.
However, databases are usually configured by the system administrator and handled by a daemon—oracle, mysql, postgresql. Here I will talk about yet another way of creating databases, without the need to start any daemons, have any user privileges and, more importantly, easily portable. This is done via sqlite.
SQLite is a library that implements a SQL engine inside your own application. This means that while the database is persistent inside a file, all the querying infrastructure is deployed along with your code and stopped when the code finishes running. The databases can be created very easily, making it easy to have multiple DBs for testing, and without the need to bother the system administrator.
sqlite has bindings for almost all popular languages and also a commandline interface which is handy for testing and debugging. The data is stored on a single file which can be deployed with your application without needing to install any standalone servers. Obviously, it is not a replacement for Oracle's solutions, but it can speed up a lot some applications which need to work querying data and don't have access to one.
Most popular software uses some kind of database to store data, as this is a super fast way to access preferences and other items. For scientific programs, it is always necessary to think twice before using one, as database design is an art on its own, and as said before, it does not suit all needs.
When used properly, a small ad-hoc database like sqlite can speed up software, make data access very easy and allow the manipulation of large, objectified, in-related data collections with simple queries instead of writing long and slow algorithms which process all the data when you only need one item.
Tags: software, programming